AI绘画的本质:从“概率抽卡”到“视觉工程”
AI绘画是通过扩散模型(Diffusion Models)或生成对抗网络(GANs)将文本描述转化为视觉图像的技术。其本质是利用海量数据训练,在潜在空间中重建概率分布,从而生成符合人类审美逻辑的像素阵列。到2026年,AI绘画已从随机的“咒语生成”进化为精准的“视觉工程”,成为一个能实时迭代、具备空间逻辑的创作系统。
核心矛盾已从“能否画出好图”转向“如何定义创作”。如果仅为了填补页面空白而使用AI,结果往往缺乏灵魂。在专业艺术家看来,单纯依赖生成并轻微润色的图像依然不自然,因为模型在模拟“结果”而非理解“意图”。
潜空间扩散模型的工作原理
理解潜空间扩散模型(Latent Diffusion Model)有助于掌握其工作原理
该模型并非直接绘制像素,而是在压缩的数学空间中进行反向去噪。当你输入特定描述时,模型在潜空间中寻找相关特征向量,通过U-Net网络将随机噪声引导至该区域。这种机制导致AI在处理手指数量、复杂透视点等空间关系时仍有概率偏差,尽管最新版本已大幅缓解此问题。
工业级实操路径:构建视觉控制流
想要进入该领域,建议放弃寻找“万能咒语”,转而构建视觉控制流。以Stable Diffusion 3.5及其集成环境为例,实操路径分为以下三个核心步骤:
第一步:构建结构化提示词体系

生产级提示词应遵循结构化公式:主体描述(Subject)+ 场景环境(Environment)+ 材质光影(Lighting/Material)+ 艺术风格(Style)+ 技术规格(Technical Specs)。
为了保证生成质量,建议参考以下参数配置:
| 参数名称 | 推荐范围 | 影响效果 |
|---|---|---|
| 采样步数 (Sampling Steps) | 25-40 步 | 过低则模糊,过高易出现伪影 |
| CFG Scale | 5-8 | 控制指令遵循度,过高会导致色彩过饱和 |
| 推荐采样器 | DPM++ 2M SDE Karras | 保证细节稳定性和图像质量 |
第二步:利用 ControlNet 掌控空间结构

ControlNet 通过参考图强制规定形状、姿势或深度,解决了不可控性的痛点。用户可通过上传姿态参考图(Pose Map)或线稿图(Canny Edge)来提取轮廓线,从而精准引导生成结果。
第三步:通过局部重绘(Inpainting)精修细节
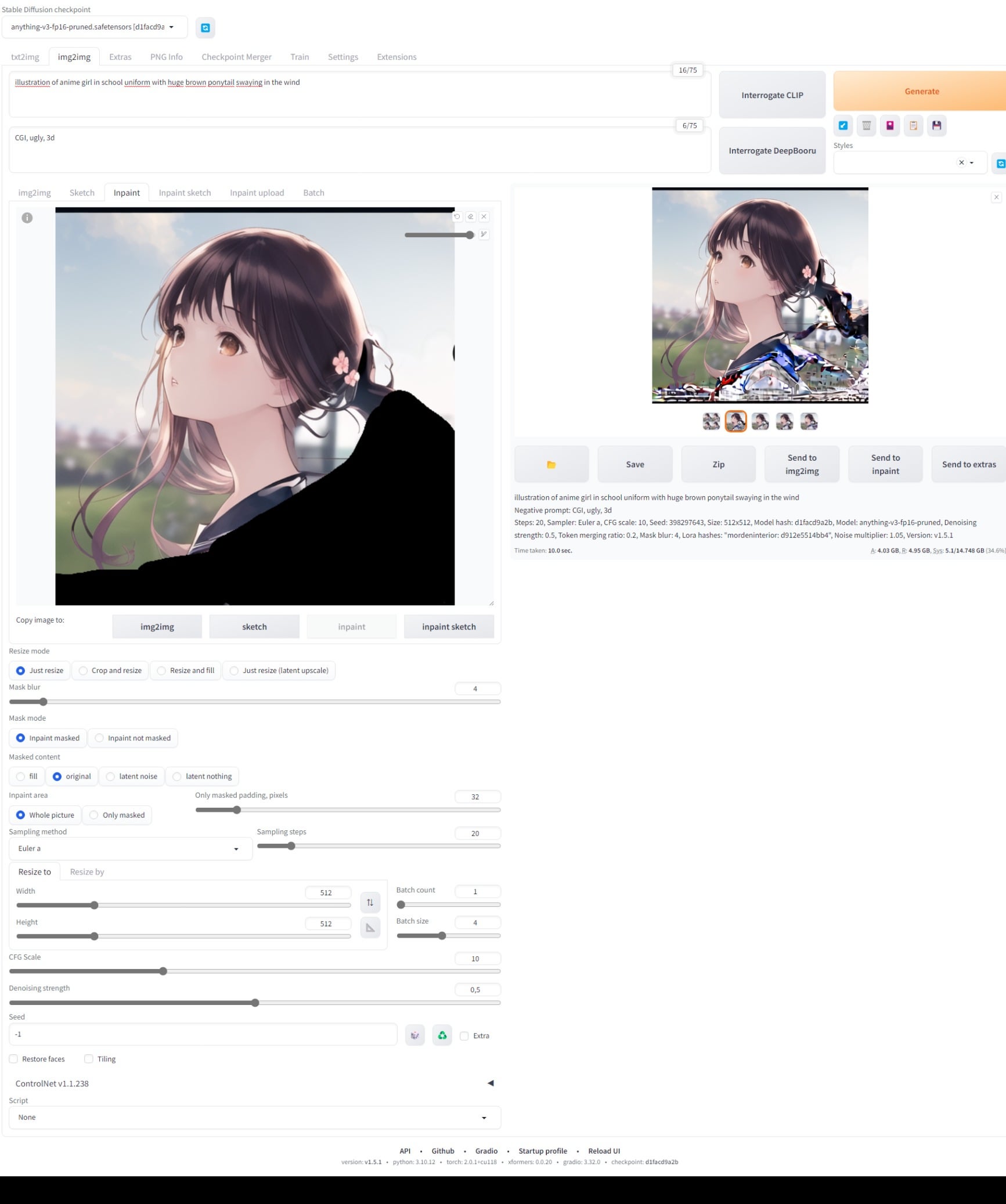
商业交付级图像必须经过局部重绘。通过掩码刷涂抹扭曲的部分(如手指或眼神),并输入修正提示词(如 "perfectly detailed human hand")进行精准修复。
- 0.3: 适合修正微小光影偏差。
- 0.4: 建议采取多次迭代策略,确保过渡自然。
- 0.7: 适合更换物体或修正严重畸形。
工具选择与局限性分析
不同工具的适用场景存在显著差异,创作者应根据需求选择:
- Midjourney v7: 擅长艺术感与氛围感,适合创意总监快速产出概念草图。
- Stable Diffusion 系列: 支持本地部署及 LoRA 库,适合需要像素级精准控制的专业设计师。
- Adobe Firefly: 采用授权图像训练,适合对法律版权风险敏感的企业级应用。
尽管功能强大,AI 绘画仍存在局限性。它擅长“平均值的最大化”,但在极端创新或需要注入个体情感、理解留白意境的作品中,AI 目前仅能扮演助理角色。
如何解决 AI 绘画的版权争议?
成熟的解决路径是构建私有化数据集。使用 50-100 张个人作品训练专属 LoRA 模型,将 AI 变为“风格放大器”而非简单的复制工具。当源图像全部来自用户自身时,AI 才真正成为纯粹的效率工具。
哪些场景不建议直接使用 AI 绘画?
一是需要极致精准且无时间手动修图的实时交付场景;二是强调“人类劳动价值”的艺术收藏领域,因为视觉精美的边际成本趋向于零,稀缺性大幅降低。
创作范式的转移:从执行者到导演
目前视觉设计的核心竞争力正在发生位移:单纯的“绘画技能”在贬值,而“审美能力”和“定义问题的能力”在升值。设计师的核心竞争力不再是光影刻画的真实度,而是能否通过精准指令迅速将抽象创意具象化,并判断方案的商业可行性。
创作角色正在“导演化”。

创作者从执行者变为掌控全局的导演,重心从画笔压力、颜料干湿转移到构图张力、色彩心理暗示和视觉叙事。这种转变释放了人类从重复劳动中抽离,去思考深层表达的能力。
实践建议:渐进式替代策略
对于初学者,建议采取“渐进式替代”工作流,以保留个性并利用 AI 的迭代优势:
2. 结构把控: 手动绘制核心结构或使用 ControlNet 锁定构图。
3. 材质增强: 最后利用 AI 进行局部材质细化与渲染增强。
产业融合与未来展望
AI 绘画正与 3D 建模和动态视频融合,形成“2D-to-3D-to-2D”的循环。通过神经辐射场(NeRF)或 Gaussian Splatting 技术,原画可快速转化为 3D 模型,调整视角后再渲染回 2D。这大幅降低了游戏和动画的制作成本,使独立开发者也能实现电影级视觉效果。
应对“替代焦虑”最好的办法是定义个人的“不可替代性”。AI 能画出完美的玫瑰,但无法模拟个体在特定时刻看到凋零玫瑰时的私人孤独感。这种基于生命经验的洞察,才是作品中最昂贵的部分。
建议现在就开始实践:安装本地 Stable Diffusion 环境或注册 Midjourney 账号。不要沉溺于教程,给自己设定一个具体目标(如“绘制梦中的故乡”),在尝试与修正中寻找表达的重心。